
One of the most frustrating problems in applying large language models to wearable data is also one of the most obvious. A modern wearable generates dozens of metrics across sleep, activity, physiology, and behavior, accumulated over months or years per participant. If you give an LLM all of that as context, performance degrades, costs explode, and the model gets lost in irrelevant detail [1]. If you give it too little, you forfeit exactly the kind of personalized reasoning that makes wearable data interesting in the first place.
A new paper from Carnegie Mellon and UC Irvine, powered by Centralive’s infrastructure and dataset access, proposes a structured answer to this problem: Wearable As Graph (WAG), a framework that organizes a participant’s wearable history into a personalized knowledge graph and retrieves only the query-relevant subgraph at inference time [2].
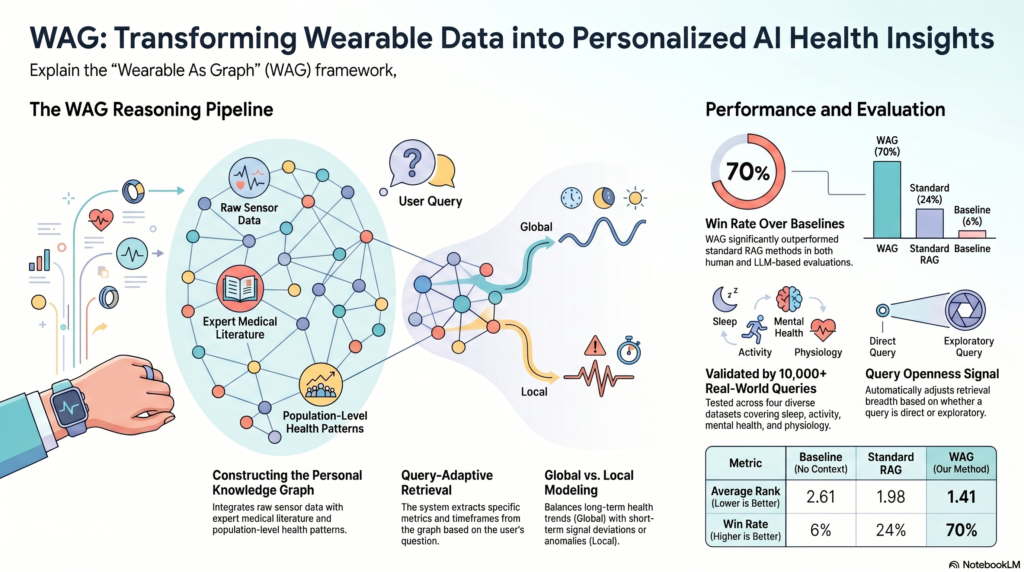
The result is a method that wins roughly 70% of head-to-head comparisons against both a no-context baseline and a standard Retrieval-Augmented Generation (RAG) approach, across more than 10,000 data-grounded queries spanning four real-world wearable datasets.
The Core Problem: Context Selection at Scale
Most existing methods for applying LLMs to wearable sensing assume that the right slice of data is already on the table. Researchers manually prepare context tailored to a specific task, often a single metric over a defined window, and feed it to the model. That works at small scale. It does not work for an always-on, always-listening digital health platform where a user might ask, in natural language, “why have I been so tired lately?” The system has to figure out, on its own, which of the 50 plus available metrics matter, over what time window, and in what relational context.
This is fundamentally a retrieval problem, not a modeling problem. The LLM is capable of reasoning over time-series data [3]. What it lacks is a principled way to be handed the right data in the first place.
The WAG Approach in Plain Terms
WAG addresses this in four steps.
1. Build a personalized knowledge graph (PKG). Each node represents a health metric (heart rate, sleep efficiency, mood, mental fatigue, and so on), enriched with definitions, normal ranges, and recommendations pulled from trusted medical sources like UMLS and curated web databases [2]. Edges represent the relationships between metrics, with weights initialized from prior medical knowledge and then continuously updated as more population and individual data accrue.
2. Parse the user’s query. An LLM extracts four structured components from any natural-language query: which metrics are involved, what time window applies, what the reference timestamp is, and an “openness score” that captures how exploratory the question is. “Did I sleep well last night” is a low-openness binary question. “Why am I feeling stressed lately” is high-openness and invites multi-factor exploration.
3. Retrieve the right subgraph. WAG identifies the primary nodes that match the query, then expands outward to neighboring nodes using edge weights that combine two signals:
- Global modeling via a Hierarchical Bayesian Model that integrates prior medical knowledge, population-level correlations across all subjects, and the individual user’s own historical patterns. This captures stable, long-term relationships.
- Local modeling that captures short-term deviations and anomalies in the recent window, modulated by the openness score so the system pays more attention to abnormal signals on exploratory queries.
4. Generate. The retrieved subgraph, populated with the user’s actual sensor values, is passed to the LLM as structured context for the final response.
Why the Bayesian Layer Matters
The Hierarchical Bayesian Model is what makes WAG genuinely personalized rather than merely retrieval-augmented. For each user, the edge weight between two metrics is updated in two stages: first by population data (how strongly are these metrics correlated across everyone in the dataset?), then by the individual’s own data (how strongly are these metrics correlated for this specific user?). The result is a posterior that respects medical priors when individual data is sparse, leans on population patterns as more data accrues, and ultimately reflects the individual’s idiosyncratic physiology when enough personal history is available.
Ablation studies in the paper confirm this matters: the combined global weighting (W_global, integrating prior, population, and individual) consistently outperforms any single source, with the ranking W_global > W_prior > W_pop > W_ind holding across all four datasets and statistically significant at p = 4.52 × 10⁻⁸ [2].
Results
The team evaluated WAG against two comparison conditions:
- Baseline: LLM receives only the relevant personal data, no external knowledge.
- RAG: Standard retrieval-augmented generation, pulling information directly related to the primary detected entity.
- WAG: The graph-based, query-adaptive approach.
Across all four datasets (IFH Affect [4], PMData [5], LifeSnaps [6], and Globem [7]), WAG reduced the average overall rank to approximately 1.4 versus 2.0 for RAG and 2.6 for the baseline, with a win rate of nearly 70%. The advantage was most pronounced on the kinds of queries where context-aware reasoning matters most: trend analysis, comparative insight, anomaly detection, and exploratory analysis. On queries with high openness scores and high abnormality metrics, WAG’s win rate exceeded 80% in several categories.
A human evaluation by three medically-trained annotators tracked the LLM-based judgments closely on the main experiment, though inter-rater reliability was modest (a known and well-documented challenge in evaluating open-ended health responses).
Qualitative Examples That Highlight the Difference
Two examples from the paper illustrate why this approach matters in practice.
When asked “what factors might be causing the significant deviations in my circadian rhythm patterns over the past 30 days,” the baseline and standard RAG approaches either failed to retrieve sufficient context or surfaced only the directly-named metric. WAG instead traversed the graph to surface related signals: maximum distance from home, PANAS negative affect, radius of gyration, active time, and number of phone unlocks. The resulting response could weave together behavioral, mobility, and affective context rather than answering in isolation.
Even more striking: when asked “how is my engagement levels over the past week,” the primary node (engagement) had no direct sensor data. The baseline and standard RAG both returned essentially “no data available.” WAG instead reached for graph-connected proxies (steps, energy expenditure, active time, mental fatigue) and produced a substantive answer grounded in the metrics that actually existed in the user’s data.
Why This Matters for Wearable-Based Research and Digital Health
Three implications stand out for anyone building research deployments or digital health products on top of wearable data.
First, the field is moving past the era of hand-curated, single-metric LLM prompts. As wearables expose more raw and derived signals through SDKs (Garmin’s raw BBI and accelerometry, Fitbit’s SDK-level access, research-grade ring streams), the bottleneck shifts from data availability to data selection. WAG provides a principled, query-adaptive answer.
Second, the Bayesian personalization layer offers a concrete path for handling the well-known problem that consumer wearable algorithms are trained on healthy young adults and generalize poorly to clinical populations [8]. By blending prior, population, and individual data, WAG naturally adapts its retrieval as more individual data becomes available, without retraining the underlying LLM.
Third, the personalized knowledge graph itself is reusable infrastructure. A clinician can add individualized thresholds (e.g., a custom blood pressure target for a specific patient). A user can annotate contextual interpretations of their own data. The graph becomes a structured interface between human expertise, lived experience, and large language models, rather than a one-shot prompt-engineering exercise.
What’s Next
The authors flag two main limitations: factual correctness of generated responses was not manually verified (a labor-intensive task requiring extensive domain expertise), and human inter-rater reliability for open-ended health responses remains modest, complicating evaluation. Both are honest acknowledgments of where the field stands.
For Centralive, this work is part of a broader thesis: that the right software layer between raw wearable signals and clinical or behavioral insight is structured, personalized, and query-adaptive, rather than a hand-coded analysis pipeline rebuilt for every new study. WAG is one early instantiation of that vision.
Read the Paper and Presentation Slides
The full paper, including the formal Hierarchical Bayesian derivation, all experimental tables, and qualitative examples, is available on arXiv:
Lu, Z., Abbasian, M., & Rahmani, A. M. (2026). Query-Conditioned Graph Retrieval for Contextualized LLM Reasoning in Personalized Wearable Data. arXiv:2605.18763. https://arxiv.org/abs/2605.18763
This research was powered by Centralive’s wearable data infrastructure and benchmark datasets.
References
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 157–173. https://doi.org/10.1162/tacl_a_00638
- Lu, Z., Abbasian, M., & Rahmani, A. M. (2026). Query-Conditioned Graph Retrieval for Contextualized LLM Reasoning in Personalized Wearable Data. arXiv:2605.18763. https://arxiv.org/abs/2605.18763
- Gruver, N., Finzi, M. A., Qiu, S., & Wilson, A. G. (2023). Large Language Models Are Zero-Shot Time Series Forecasters. Thirty-seventh Conference on Neural Information Processing Systems. https://openreview.net/forum?id=md68e8iZK1
- Labbaf, S., Abbasian, M., Nguyen, B., Lucero, M., Ahmed, M. S., Yunusova, A., Rivera, A., Jain, R., Borelli, J. L., Dutt, N., et al. (2024). Physiological and emotional assessment of college students using wearable and mobile devices during the 2020 COVID-19 lockdown: an intensive, longitudinal dataset. Data in Brief, 110228.
- Thambawita, V., Hicks, S. A., Borgli, H., Stensland, H. K., Jha, D., Svensen, M. K., Pettersen, S. A., Johansen, D., Johansen, H. D., Pettersen, S. D., et al. (2020). PMData: a sports logging dataset. Proceedings of the 11th ACM Multimedia Systems Conference, 231–236.
- Yfantidou, S., Karagianni, C., Efstathiou, S., Vakali, A., Palotti, J., Giakatos, D. P., Marchioro, T., Kazlouski, A., Ferrari, E., & Girdzijauskas, Š. (2022). LifeSnaps, a 4-month multi-modal dataset capturing unobtrusive snapshots of our lives in the wild. Scientific Data, 663.
- Xu, X., Zhang, H., Sefidgar, Y., Ren, Y., Liu, X., Seo, W., Brown, J., Kuehn, K., Merrill, M., Nurius, P., et al. (2022). GLOBEM dataset: multi-year datasets for longitudinal human behavior modeling generalization. Advances in Neural Information Processing Systems, 24655–24692.
- Kim, Y., Xu, X., McDuff, D., Breazeal, C., & Park, H. W. (2024). Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data. Proceedings of the fifth Conference on Health, Inference, and Learning, 522–539. https://proceedings.mlr.press/v248/kim24b.html
Sign up for the Centralive Newsletter: https://newsletter.centralive.health/signup



